
|
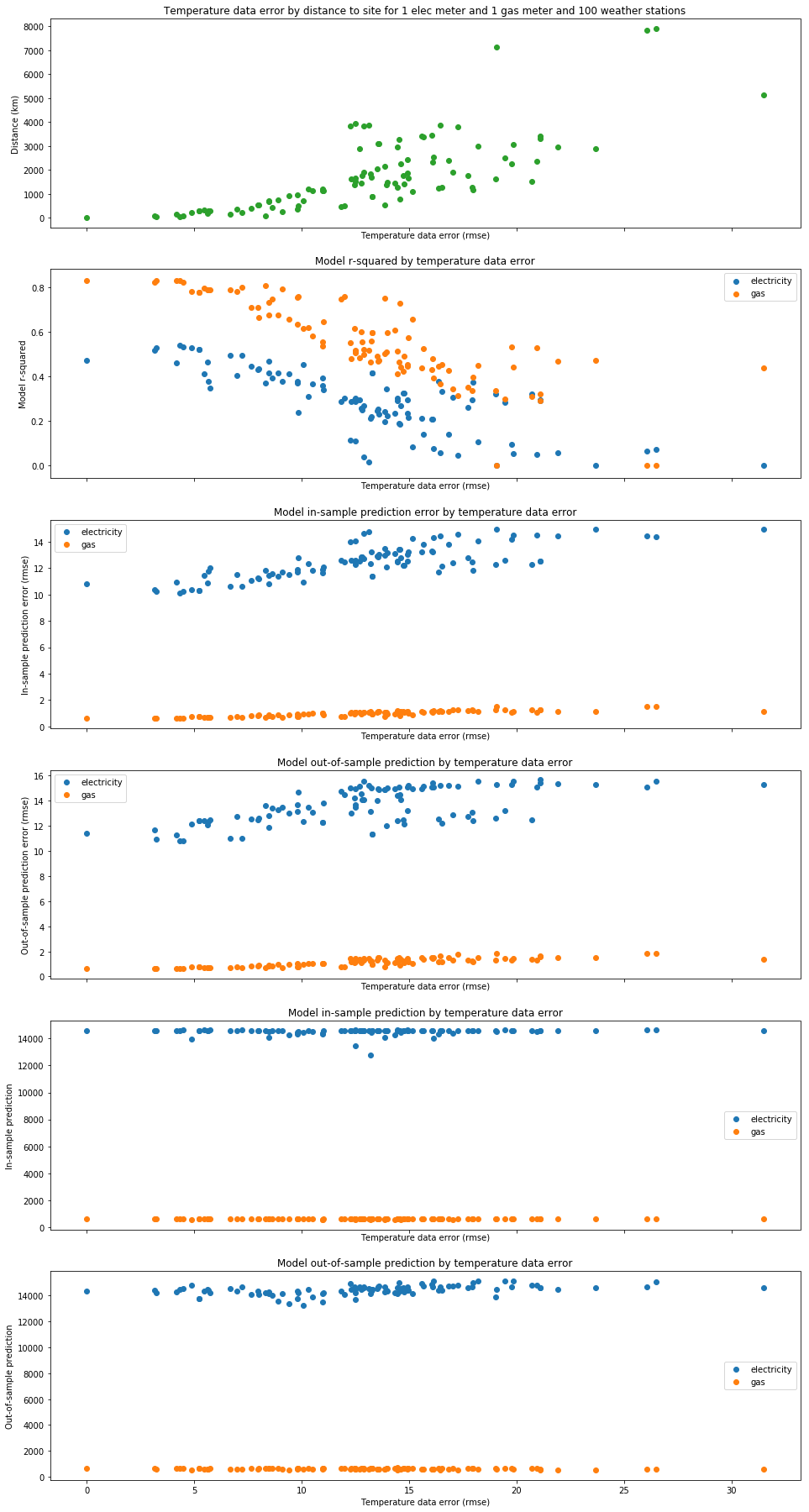
Week Four CalTRACK Update During week 4, we received some interesting results from tests on daily and billing period methods. In this week’s blog post, we analyze the test results and determine their effect on our proposed daily and billing period methods. Additionally, we will introduce the new topic of building qualifications. (Participant Homework can be found at the bottom of this post) Test Results: 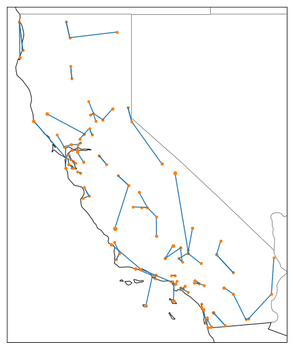 Weather Station Mapping: Because we do not have access to weather data at the location of each site, the best approach for estimating a site’s temperature is to use data from nearby, high-quality weather stations. The most intuitive way to “map” which primary and backup weather stations to use for a site is to simply choose weather stations with the shortest distance to the site. Some argue that this simple method fails to account for the unequal distribution of weather patterns over space. For example, imagine a mountain home is technically closer to a weather station in the desert valley than to another weather station in the mountains. We might expect the house’s weather data to be better approximated by the mountain weather station than the desert valley weather station, despite it being further away. To account for this phenomenon, another proposal is to use pre-defined climate zones throughout states to choose the closest primary and backup weather stations that are within that site’s climate zone. Two proposals for mapping a site’s weather stations:
To empirically inform our decision, we ran a simulation for each mapping method where we used the actual weather stations as units, instead of the sites, and compared each method’s accuracy. Our results show that both proposed methods provide very similar results, with “Method 1” and “Method 2” providing a perfect match 53% and 56% of total matches respectively. These results indicate that there are not significant accuracy reductions from choosing the simpler “Method 1".
Results:
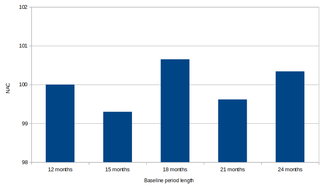 Maximum Baseline Period Length: There have been discussions about defining a maximum baseline period because excessively long baseline periods may absorb unnecessary variation that could obscure our model predictions. To determine the effect of longer baseline periods, we calculated baselines of 12, 15, 18, 21, and 24 months. The graph below shows that normalized annual consumption (NAC) can be unstable as we increase the baseline period. Recommendation:
Degree Day Balance Points: A proposed new method for CalTRACK 2.0 is to use variable balance points instead of fixed balance points on the HDD and CDD variables. In the figure below, we can see that buildings tend to cluster at the limits of balance point degree ranges, which implies that some results may be constrained by small search grids. When the degree range is expanded, the results displays a distribution that is closer to Gaussian. 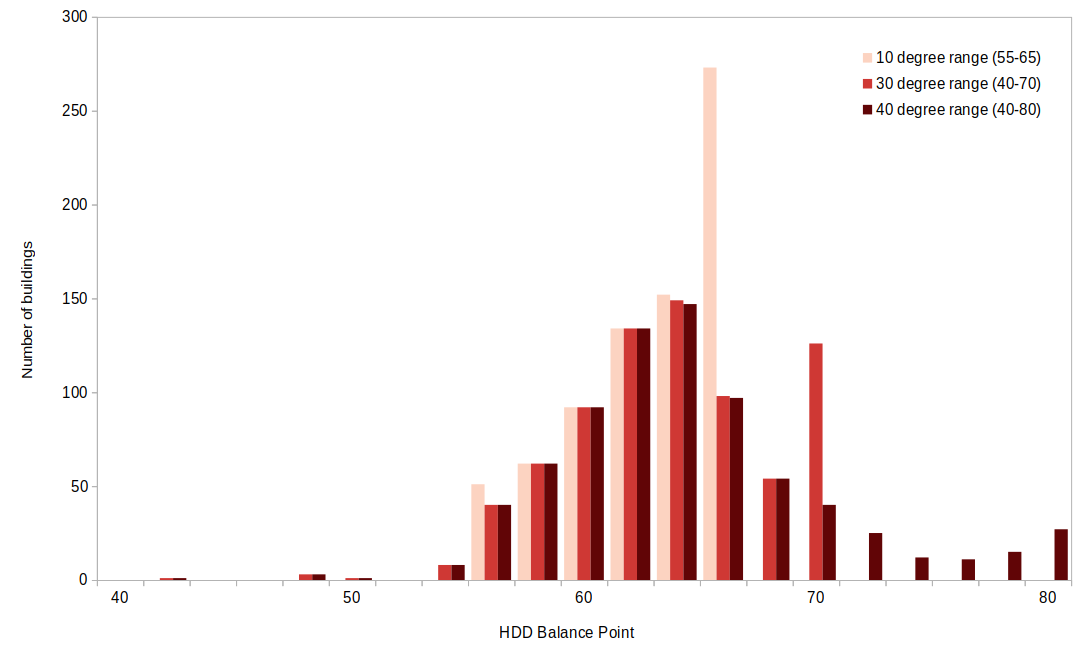 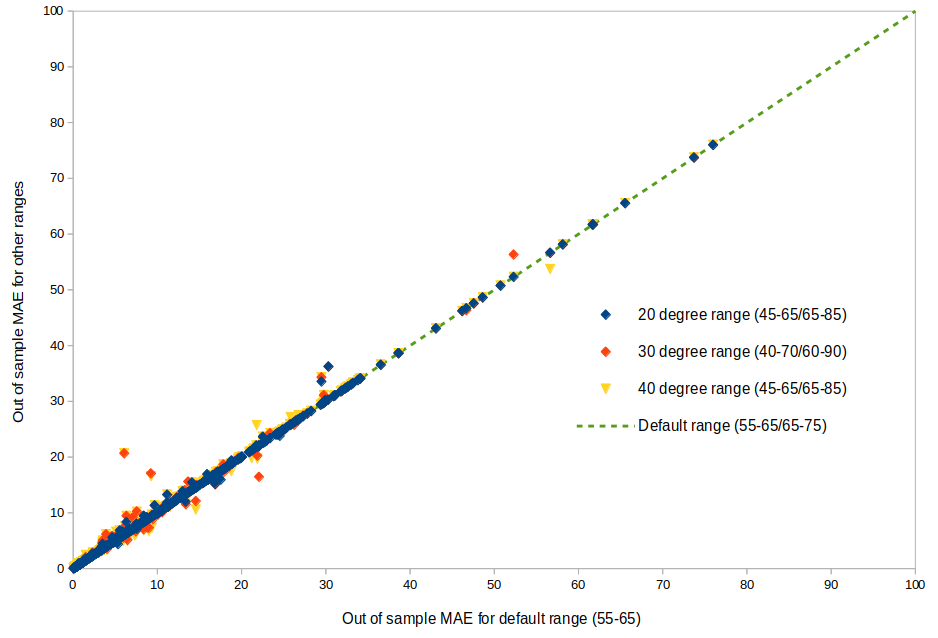 Although expanding the search grid may uncover a balance point that yields a higher R-squared, the figure on the right shows that these results have a nominal impact on model fit. Regardless, variable balance points are advised because they provide better balance point estimates, which have more interpretation value. Recommended Allowable Ranges: HDD: 40-80 CDD: 50-90
In CalTRACK 2.0, we intend to eliminate the p-value screen and select models strictly on the adjusted R squared. We suggest this change because the p-value screen does not increase our model fit and we lose valuable information on estimators when we drop them due to high p-values, as well as eliminating many weather-sensitive model fits. Handling Billing Data: Modeling using billing data was underspecified in CalTRACK 1.0. We are proposing to include explicit instructions on modeling using billing data that includes billing periods of different lengths using weighted least squares regression. New Topics: Building Qualification: In this coming week, we will begin our examination of building qualification screening criteria. The CalTRACK methods were initially tested using residential buildings and are currently mainly used to quantify energy savings for residential units and small commercial buildings. The limits of the CalTRACK methods for measuring savings in commercial or industrial buildings (where weather is likely to be a poorer predictor of energy consumption) has been subject to less scrutiny. Our goal is to create empirical tests for determining the energy usage patterns in buildings that qualify a building for CalTRACK methods and exclude those that would be better estimated with different methods. We are looking forward to your input on potential methods and tests to define buildings that qualify for CalTRACK. Some questions that need to be addressed (and we welcome additional questions):
We are looking forward to your input on building qualification in this coming week. There will be a lot to discuss on GitHub Issues. We would like to test proposed building qualification methods empirically before making decisions, so it is important to make method and testing suggestions as soon as possible. HOMEWORK:
1 Comment
|
The purpose of this blog is to provide a high-level overview of CalTrack progress.
For a deeper understanding or to provide input on technical aspects of CalTrack, refer to the GitHub issues page (https://github.com/CalTRACK-2/caltrack/issues). Recordings
2019 CalTRACK Kick Off:
CalTRACK 2.0 July 19, 2018 June 28, 2018 June 7, 2018 May 24, 2018 May 3, 2018 April 12, 2018 March 29, 2018 March 15, 2018 March 1, 2018 February 15, 2018 February 1, 2018 Archives
March 2024
|

 RSS Feed
RSS Feed
